
皆さんこんにちは。今回は、OpenCVとdlibを使ったface_recognition(顔認識)を使っていこうと思います。
windowsでの方法と、Linux(Ubuntu, 試してないけどMAC)での方法を書きます。
今回すること
webcam(ウェブカメラ)を使ってリアルタイムにあらかじめ保存しておいた人の顔を識別することをやっていきます。
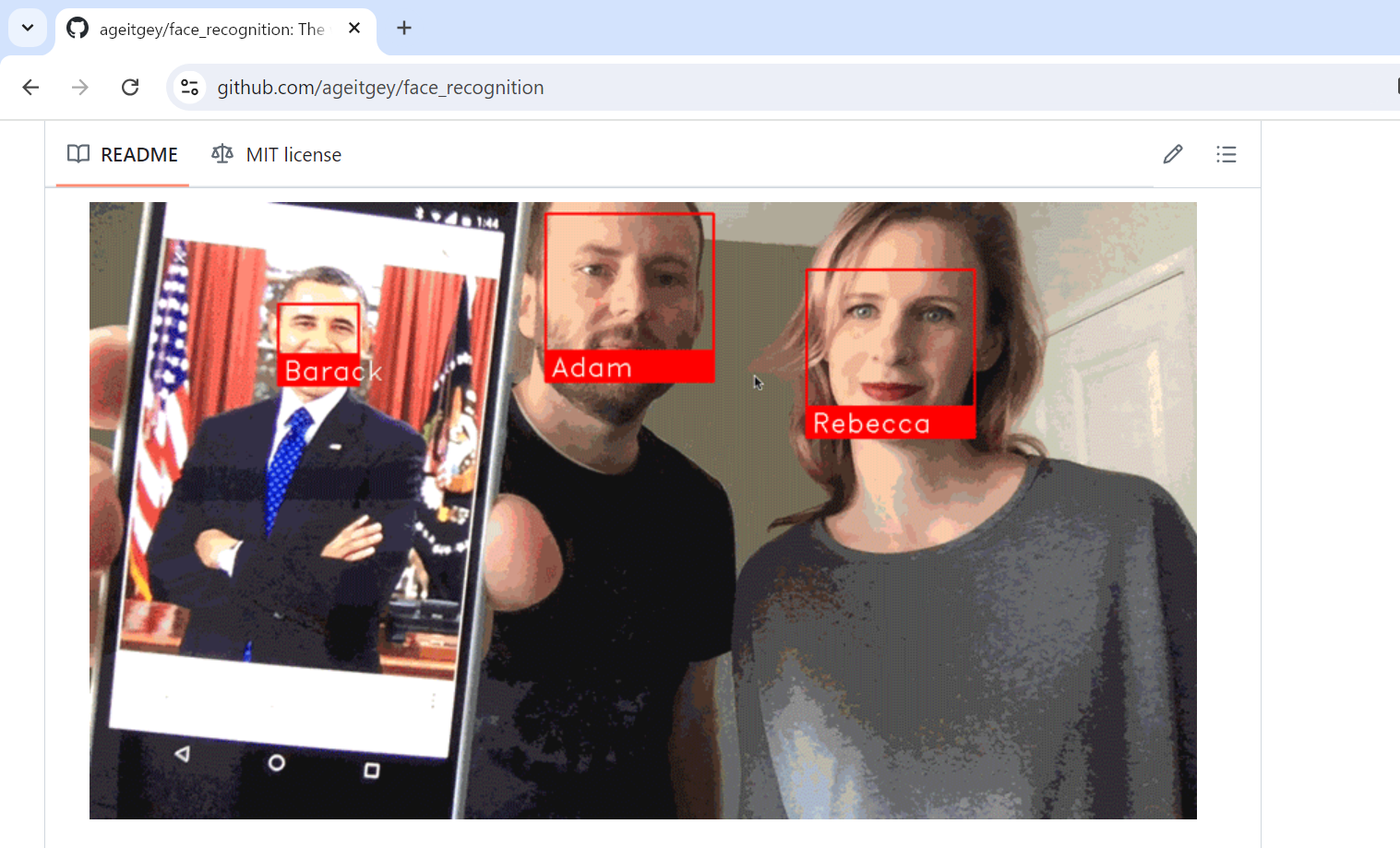
こんな感じ↓(公式githubより)

このライブラリについては公式で、
世界で最もシンプルな顔認識ライブラリを使って、Pythonやコマンドラインで顔を認識・操作することができるライブラリです。
dlibのディープラーニングを用いた最先端の顔認識を使用して構築されており、このモデルはLabeled Faces in the Wildベンチマークにて99.38%の正解率を記録しています。
シンプルな
https://github.com/m-i-k-i/face_recognition/blob/master/README_Japanese.mdface_recognitionコマンドラインツールも用意しており、コマンドラインでフォルダ内の画像を顔認識することもできます。
と書かれています。日本語の説明があるのはうれしいですね。
また、公式のサンプルはエラーが出で動かないのでこちらのコードを使っていきます。
下準備
python3がインストールされていることが前提です。
windows:
https://apps.microsoft.com/detail/9nrwmjp3717k?hl=en-us&gl=US
linux系:
ターミナル(端末)で実行する。
sudo install python3インストール(linux)
自動インストール
https://github.com/rintaro-s/webcam_face_recognition
できる人は↑のリンクからダウンロードしちゃってください。
一応使い方を書いておきます。
opencv-python,dlib,face_recognitionがすでに入っている場合は、
git clone https://github.com/rintaro-s/webcam_face_recognition.gitでcloneするだけでいいです。入っていない場合は、
git clone https://github.com/rintaro-s/webcam_face_recognition.git
解凍>中に入ってターミナル開く
chmod +x ./install.sh
sudo ./install.shと実行して下さい。まあまあ時間がかかります。
手動でする
https://github.com/m-i-k-i/face_recognition/tree/master?tab=readme-ov-file#installation
こちらの方法を見てやって下さい。自分はこのやり方ではよくわからなかったのでおすすめできません。
windowsでのインストール
Microsoft Visual Studio c/c++をインストールします。
https://visualstudio.microsoft.com/ja/
CMakeをインストールします。
https://cmake.org/

パッケージとコードをダウンロードします。コマンドプロンプトで実行してください。
pip install opencv-python
pip install dlib
pip install face_recognition
#pythonのダウンロード
git clone https://github.com/rintaro-s/webcam_face_recognition.gitPR


実際に使う
ダウンロードしたファイルの中にはcv.pyとsimple.pyがあるはずです。
cv.pyは、こちらを編集したもので、処理速度が速いです。そのかわりコードが複雑になって、性能が低下しています。
simple.pyは、こちらを編集したもので、少し重い代わりに最低限のコードになっています。
それぞれの違いは、webcamの動画のスケールを1/4にして処理速度を向上しています。
ダウンロードしたcv.pyコードの中身を見てみましょう。
※コメントは訳しました
import face_recognition
import cv2
import numpy as np
# これはウェブカメラからのライブビデオで顔認識を実行するデモです。少し複雑ですが、パフォーマンスを向上させるための基本的な調整が含まれています:
# 1. 各ビデオフレームを1/4の解像度で処理し(ただし、フル解像度で表示します)
# 2. ビデオの毎フレームごとに顔を検出するのではなく、隔フレームごとに検出します。
# 注:この例では、ウェブカメラから読み取るためにOpenCV(cv2ライブラリ)がインストールされている必要があります。
# OpenCVはface_recognitionライブラリを使用するためには*必要ありません*。この特定のデモを実行したい場合にのみ必要です。
# インストールに問題がある場合は、OpenCVを必要としない他のデモを試してみてください。
# ウェブカメラ#0(デフォルトのもの)への参照を取得します
video_capture = cv2.VideoCapture(0)
# サンプル画像を読み込み、それを認識できるように学習させます。
a_image = face_recognition.load_image_file("a.jpg")
a_face_encoding = face_recognition.face_encodings(a_image)[0]
# 2番目のサンプル画像を読み込み、それを認識できるように学習させます。
b_image = face_recognition.load_image_file("b.jpg")
b_face_encoding = face_recognition.face_encodings(b_image)[0]
# 既知の顔のエンコーディングとその名前の配列を作成します
known_face_encodings = [
a_face_encoding,
b_face_encoding
]
known_face_names = [
"a",
"b"
]
# いくつかの変数を初期化します
face_locations = []
face_encodings = []
face_names = []
process_this_frame = True
while True:
# ビデオの単一フレームを取得します
ret, frame = video_capture.read()
# 時間を節約するために隔フレームのみを処理します
if process_this_frame:
# 顔認識処理を高速化するためにビデオフレームのサイズを1/4にリサイズします
small_frame = cv2.resize(frame, (0, 0), fx=0.25, fy=0.25)
# 画像をBGRカラー(OpenCVが使用する)からRGBカラー(face_recognitionが使用する)に変換します
rgb_small_frame = small_frame[:, :, ::-1]
code = cv2.COLOR_BGR2RGB
rgb_small_frame = cv2.cvtColor(rgb_small_frame, code)
# 現在のビデオフレーム内のすべての顔と顔のエンコーディングを見つけます
face_locations = face_recognition.face_locations(rgb_small_frame)
face_encodings = face_recognition.face_encodings(rgb_small_frame, face_locations)
face_names = []
for face_encoding in face_encodings:
# 顔が既知の顔と一致するかどうかを確認します
matches = face_recognition.compare_faces(known_face_encodings, face_encoding)
name = "Unknown"
# # 既知の顔エンコーディングで一致が見つかった場合は、最初のものを使用します。
# if True in matches:
# first_match_index = matches.index(True)
# name = known_face_names[first_match_index]
# あるいは、新しい顔に最も近い距離を持つ既知の顔を使用します
face_distances = face_recognition.face_distance(known_face_encodings, face_encoding)
best_match_index = np.argmin(face_distances)
if matches[best_match_index]:
name = known_face_names[best_match_index]
face_names.append(name)
process_this_frame = not process_this_frame
# 結果を表示します
for (top, right, bottom, left), name in zip(face_locations, face_names):
# 顔の位置を元のフレームのサイズに戻します(フレームが1/4のサイズで検出されたため)
top *= 4
right *= 4
bottom *= 4
left *= 4
# 顔の周りにボックスを描きます
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# 顔の下に名前のラベルを描きます
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255), cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0, (255, 255, 255), 1)
# 結果の画像を表示します
cv2.imshow('Video', frame)
# キーボードで'q'を押して終了します!
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# ウェブカメラへのハンドルを解放します
video_capture.release()
cv2.destroyAllWindows()
仕組みはコメントと公式ドキュメントを頼りに読み進めてください。
同ディレクトリにa.jpgとb.jpgを入れて、
実行してみましょう。

しっかりと認識されるはずです。(ほぼ塗られてるのはごめんなさい)
あとがき
ラズパイはまだ試せてないので、いけたら付け足します。
閾値等も、https://github.com/ageitgey/face_recognition/blob/master/examples/face_recognition_knn.py
これを読み解いたら行けるらしいのですが、まだできていません。
できた人がいたらコメントかdiscordで教えてくれると嬉しいです。
ライセンス表記

とある高専生。
AIとネットが好き。
将来はAIの妹と火星に住みたい。
discord : r_nightcore
このサイトの管理者。
コメント