

みなさんこんにちは。
皆さんは、チャットAI使っていますでしょうか?最近Lama4が出て、「MoEアーキテクスチャが使われててなんかすごい!」と評価されてる印象ですが、友達が「時代はTransformerじゃなくてMoEですよ」と言っていて「ん?」となったので自分なりに整理するためにまとめてみました。
なにがあるんだろ
とりあえず、今回の登場人物を紹介します。
- Transformer
- MoE(Mixture of Experts)
最初に確認したいのですが、これらはすべて同レベル(階層・レイヤー?)の話ではありません。
具体的に言うと、
Transformerは自己完結したニューラルネットのアーキテクチャで、MoEはその中に組み込むこともできる、構造上の工夫・設計思想といった側面が強いです。
MoEが使われているものはGrokとかLLama4しか知らないですね(細かく言うとSwitch TransformerやGLaM、Mistral AIのMixtralなどにも使用されています)
Transformerは、GPTを含む現代の多くの大規模言語モデル(LLM)の基礎となっているアーキテクチャです。ChatGPTやClaudeも、Transformerをベースとしたモデルを使用しています。
それを踏まえて見ていきましょう。
事前知識
説明に必要な用語たちです。
トークン:意味を持つものを分けたもの。

こんな感じのやつですね。それぞれの色ごとに一つの意味を持つ単語が分類されています。
言葉のベクトル:単語をベクトル(すべての語群の中の座標)としてみること。
有名な例では、「東京」ー「日本」+「アメリカ」=「ワシントンD.C」などですね。
詳しくは、 https://qiita.com/satken2/items/d8b3e687e0ac4e55bcec こちらのページがわかりやすいです。
Transformer
このページにすべての説明を書くと、ページの長さがとんでもないことになるので簡単な概念を主に解説していきます。私が説明できないだけというのもありますが。
〜〜トークンくんの冒険〜〜
(平日の昼あたりにやってるNHKの勉強番組のようなアニメを想像しながらお読みください)
トークンくんは文章「私は猫が好き。彼女は犬が好き」からやってきた「私」だよ。仲間たち(「は」「猫」「が」「好き」「彼女」「は」「犬」「が」「好き」)と一緒にTransformerさんのところにやってきた!
エンベディングの部屋で準備
Transformerさんの最初の部屋で、トークンくんは「エンベディング」という服に着替えるよ。これはトークンくんを数字(ベクトル)に変える作業。「私」は例えば[0.1, 0.5, …]みたいな数字になる。さらに、位置情報(「私は文章の前から1番目だよ」)も加えられて、準備完了!
アテンションさんとの出会い(Self-Attention)
次に、アテンションさんがやってきて言うよ。「トークンくん、文章の中で誰と関係が深いか見てみよう!」
トークンくん(「私」)は、「は」や「猫」とどれくらい関係があるかを計算。注意さんは「クエリ」「キー」「バリュー」という道具を使って、トークンくんと仲間たちの関係を点数付けするよ。
- 「私」と「は」は関係が強い(点数高め)。
- 「私」と「好き」もちょっと関係あり(点数そこそこ)。
- 「私」と「彼女」はちょっと違う(点数ビミョー)。
この点数をもとに、トークンくんは仲間たちから重要な情報を集めて、自分の新しい姿(ベクトル)をアップデート!
層さんのトレーニングジム(Feed-Forwardと正規化)
注意さんとの作業が終わると、トークンくんは層さんのジムに行くよ。
ジム1(Feed-Forward):トークンくんたちは、「注意さん」とのグループワークのあと、今度は一人ずつ別の部屋に入って、パーソナルトレーナーとマンツーマントレーニングを受けます。
- まず体を伸ばす(次元を増やす)
→ トークンくんの情報を、一時的にもっと大きな空間で表現し直します。
→ たとえば、「『猫』って言葉だど、猫には“動物っぽさ”“可愛さ”“家で飼うことが多い”」みたいな、いろんな側面を一度全部広げてみる感じ。 - 最後に、体を元の形に戻す(次元を縮める)
→ 広げた情報を、またトークンくんのサイズに戻します。でも、最初よりちょっと賢くなってる!
ジム2(正規化と残差接続):トレーニングを終えたトークンくんは、そのまま突っ走ると暴走しがち。だから、「元の自分(残差)」を少し残しつつ、「新しくなった自分(出力)」とまぜてバランスを取ります。
そして一人だけ意味のベクトルが突出しないために、他のトークンのベクトルと突出して変わらないように整えます。
このジムを並行して何回か繰り返して(←重要!)、トークンくんはどんどん成長!
最終ゴール:次のトークンを予測
最後に、トークンくんたちは全員で力を合わせて、次のトークンを予測するよ。「私は猫が好き。彼女は犬が好き」の次は「です」かな?
それぞれのトークンの意味のベクトルをみて、その次に来そうなベクトル(方向)を考えるよ。そして次に来そうなそれっぽいやつを選ぶんだ。
Transformerさんは、トークンくんたちの情報をまとめて、次の言葉を予想するんだ。
〜〜〜
いかがでしょうか。
本当に余談ですが、私は中学の時に賞金につられて小説を書きまくってたので、物語を作るのが好きです。
「ジム」あたりは、具体的な仕組みを物語で書くのは難しかったので、けっこう変な文章になってしまいました。ごめんなさい。
とりあえず、ちょっと補足しておきましょう。
アテンションについてですが、簡単に「ベクトル化する」と書かれていますが結構重要です。特に日本語で。
「私ははしを渡る」「私ははしを持つ」という文章は両方、「はし」という単語が使われていますが「橋」か「箸」かは「はし」という単語を見ただけではわかりません。そこで、周りの「渡る」や「持つ」のベクトルの近くにある「はし」を検索すればどっちか分かるやん!みたいな感じに識別できるようにするのがいいですね。(語彙力の底)
興味がある方はこの動画を参考にしてください。とてもわかりやすいです。
MoE!
皆さんの大好きな「萌え(*´▽`*)」ではありませんよ。Mixture of Experts(専門家の混合)でMoEです。せっかくなので、賛否ある「AIに記事を書かせる」こともしてみましょうか(?)
〜〜トークンくんと、エキスパート(専門家)たち〜〜
「私は猫が好き。彼女は犬が好き。」
この文章の中からやってきたトークンくん、「私」は今、Transformerのある層にたどり着いたところ。
でも今回はちょっと特別。この層には、なんといろんな専門家(エキスパート)たちがいる道場があるのです。
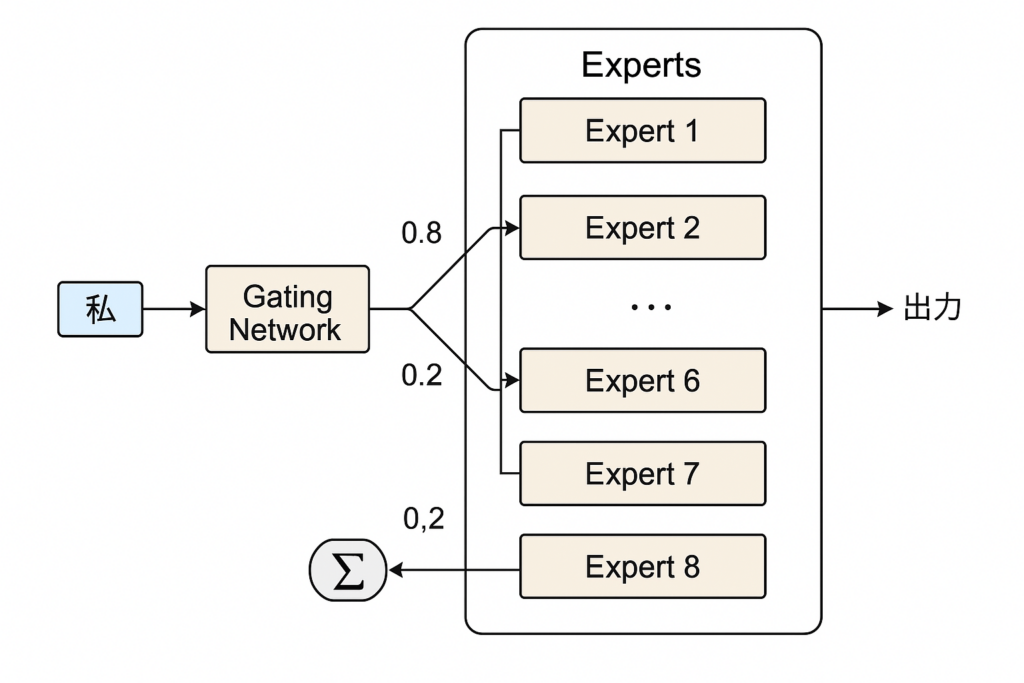
【ステップ1:門番に相談(ゲートネットワーク)】
トークンくん:「あの〜、私は『私』っていうトークンなんですけど、どの先生の道場に行けばいいでしょうか…?」
すると、門番さん(ゲートネットワーク)がトークンくんの特徴を見て、こう言います:
「あなたには、エキスパート道場3番と7番が合っていそうですね。3番に7割、7番に3割の力で行ってみましょう!」
ここで、全員の専門家を見るわけじゃなくて、一部だけ選んでもらえるのがMoEのポイント。
【ステップ2:選ばれた専門家にだけ行く(選択的計算)】
トークンくん:「よろしくお願いしますー!」
エキスパート道場3番:「おっ、『私』か。じゃあ自分の役割や文脈の中の意味を深掘りしていこうな!」
エキスパート道場7番:「『彼女』や『犬』みたいな他の人との関係性も見てみようか。」
トークンくんは、この2つの道場で、それぞれ少しずつ違う角度からトレーニング(計算)を受けます。
【ステップ3:結果を合成して出発(スパース出力)】
それぞれの道場で磨かれたトークンくんは、今度は両方の成果をバランスよく合成して、次の層へと進みます。
→ エキスパート3で鍛えられた部分 × 70%
→ エキスパート7で鍛えられた部分 × 30%
= 新しくなった「私」くん、出発!
〜〜〜
chatGPTのほうが文がわかりやすいですね(悲)
今の画像生成ってこんなにきれいに文字がかけて図もかけるんですね。すごいなー
TransformerとMoEの違い!
MoEは、Self-AttentionやPosition Encodingなど、基本的な構造は似ています。(特にMoE入りTransformerでは)また、どちらも自然言語処理や画像処理に使われるニューラルネットワークの一種です。
しかし、以下の点で違いが挙げられます。
1. Feed-Forwardの部分の構造
- Transformer:
各トークンに対して1つの固定されたFeed-Forwardネットワークを適用
→ 全トークンが同じ処理を受ける - MoE:
各トークンごとに複数の「専門家(Expert)」から一部を選んで処理
→ トークンに応じて処理が変わる(柔軟性アップ)
2. 計算の効率性
- Transformer:
全トークンで同じネットワークを使うので、パラメータ数(学習データ)は少なめに出来るけど、計算は全体にかかる - MoE:
エキスパートの数が多くても、1トークンあたり2つくらいしか使わない
→ 計算量は少ないのに、全体のモデル容量は大きい(スパースな計算)
3. モデルの柔軟性と拡張性
- Transformer:
大規模化すると、計算コストもメモリも大幅に増える - MoE:
専門家の数を増やしても計算量はあまり増えない
→ 巨大モデルを効率よく運用できる
4. トークンごとの個別対応
- Transformer:
全トークンに同じ処理=画一的な学習 - MoE:
トークンの内容に応じて処理ルートが変わる
→ 「私は」には言語系エキスパート、「猫」には動物系エキスパート、みたいな役割分担が自然にできる
なんとなく掴めて頂けたでしょうか?
要するに、
Transformerは、文の全トークンに対して、同じ構造(Self-Attention+同じFeed-Forward層)を使って一斉に処理を行う。
MoEは、その中のFeed-Forward部分を拡張し、「トークンごとに最適な専門家(サブネットワーク)を選んで処理を行う」構造になっている。
ということです。
さいごに
どうでしたでしょうか?
AIって面白いですね〜
こんな数が必要な処理ができるようになった時代もすごいですよね。
ChatGPTによる間違いチェックや二度見で気をつけてはいますが、間違った情報が含まれているかもしれないので、その時はまたコメントか連絡ください。
ありがとうございました!

とある高専生。
AIとネットが好き。
将来はAIの妹と火星に住みたい。
discord : r_nightcore
このサイトの管理者。
コメント