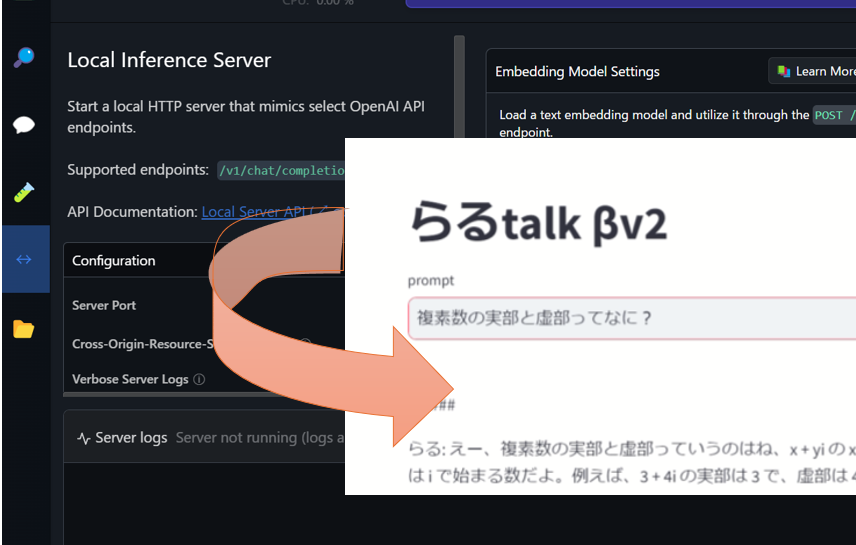

こんにちは!今回は自分がよくわからなかったLMstudioのlocal inference server機能を使ってみようと思います。あまりまだわかっていないですが、とりあえず共有したかったので書いていきます。安定したものが作れたらまた更新していくのでよろしくお願いします。
LMstudio?なにそれ?という方は、前回の記事を見るとなんとなくわかると思います
実行する準備
サーバーを起動する
まず、左側のメニューから「local server」を押します
使用したいモデルを選び、start server します
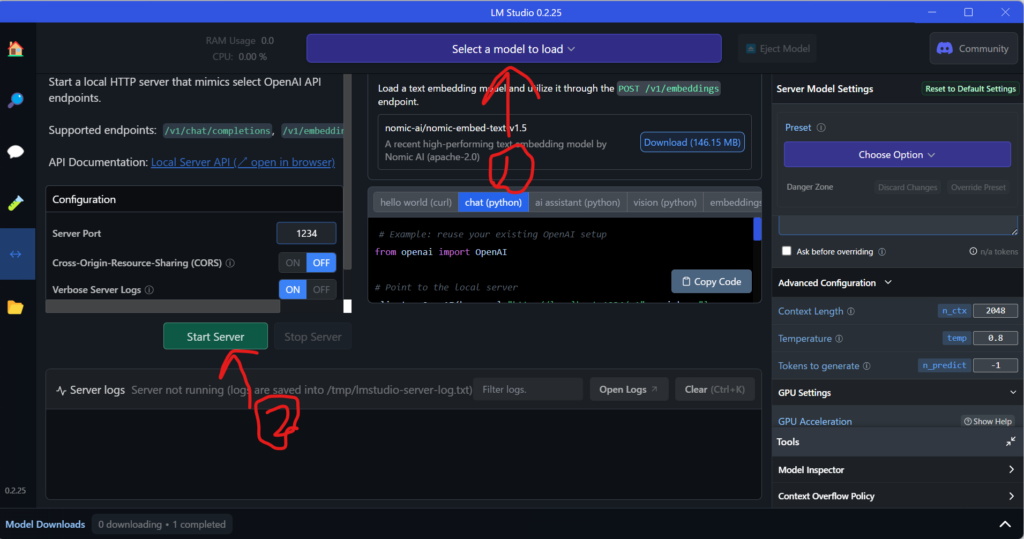
これでサーバーの起動は完了です
デフォルトではlocalhost:1234でリッスンしています。
必要なパッケージのインストール
コマンドプロンプトを開き、次のコードでパッケージをインストールします。
pip install streamlit
pip install pypdf langchain langchain_openai
pip install openai
pip install requestsLMstudioを動かしてみる
VScode上で実行する
LMstudioに表示されている例を実行してみましょう。次の日本語に訳した文で実行してみます
書き方はOpenAIと同じらしいです。(私は使ったことありませんが)
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
completion = client.chat.completions.create(
model="mmnga/tokyotech-llm-Swallow-MS-7b-instruct-v0.1-gguf",
messages=[
{"role": "system", "content": "常に韻を踏んで回答します。日本語で話します"},
{"role": "user", "content": "自己紹介をして"}
],
temperature=0.7,
)
print(completion.choices[0].message)右上の矢印、もしくはctrl alt nで実行しましょう。下のターミナルに実行結果が出てくるはずです。
PS C:\Users\s-rin\Desktop\leno> python -u lm.py
ChatCompletionMessage(content=’私はOpenAssistant、あなたの質問に答えるための言語モデルです。’, role=’assistant’, function_call=None, tool_calls=None)
次に、openaiライブラリを使用せずに投げてみましょう。個人的にこちらの方が気に入っています。
プロンプトはターミナル上で入力します。
import requests
def send_inference_request(prompt):
url = 'http://localhost:1234/v1/completions'
headers = {'Content-Type': 'application/json'}
data = {
'prompt': prompt,
'temperature': 0.7,
'max_tokens': 100
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
generated_text = response.json()['choices'][0]['text']
print('生成されたテキスト:', generated_text)
else:
print('エラーが発生しました:', response.status_code, response.text)
if __name__ == '__main__':
prompt = input('プロンプトを入力してください: ')
send_inference_request(prompt)
実行してみましょう。
PS C:\Users\—\Desktop\leno> python -u lm.py
プロンプトを入力してください: 自己紹介をして。
生成されたテキスト:
こんにちは!私は, です。日本語を話すことが好きで、日本の文化にも興味があります。今日は何をする予定ですか?
それっぽくなってきましたね。
PR

ブラウザ上で動かしてみる(注:開発中)
皆さんは何をしたくてこのページに来たでしょうか?
chatGPTのようなサイトを作りたい!
そんな人もいるかもしれません。
ですが、いろいろ試したのですがjavascriptなどでpostするとエラーが出てしまいました。
(自分のプログラムの問題な気もしますが)
なのでstreamlitというツールを使用します。pythonで簡単なサイトを作れる優れものです
今回のコードでは、チャット履歴やsystem promptは通常プロンプトにねじ込んでるのでたまに出力が変になります。
チャットデータの保存方法をまだ理解していないです。上の方にあるdata変数にてき適当な文字を入れてデータを交換してください。
import streamlit as st
import requests
import pickle
data = "b"
# チャット履歴の読み込み
try:
with open(data, "rb") as f:
chat_history = pickle.load(f)
except FileNotFoundError:
chat_history = []
# システムプロンプト
system_prompt = """
あなたは私(お兄ちゃん)の妹です。日常の会話のように、小学生のような口調で話してください。敬語は使わない。プログラム、かっこ、小説、顔文字、参考リンク等の、現実の会話で話さないものは出力しない。妹のプロフィール; {名前:らる、趣味:ゲーム(シミュレーション), 年齢:12歳,誕生日:2月14日、好きな食べ物:アイスクリーム、 スイカ、嫌いな食べ物:カレー、住所:東京都新宿区西新宿2丁目8−1,性格:基本優しいが起こると怖い}プロフィールの内容はそれを聞かれない限り答えないで。私の言ったことは、user promptで表されます。らるが話した内容だけを出力します
user prompt:
"""
def send_inference_request(prompt):
url = "http://localhost:1234/v1/completions"
headers = {"Content-Type": "application/json"}
data = {
"prompt":f"chat history:###{chat_history}###system prompt:###{system_prompt}###user prompt:###{user_input}###",
"temperature": 0.7,
"max_tokens": 100,
}
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
generated_text = response.json()["choices"][0]["text"]
return generated_text
else:
print("エラーが発生しました:", response.status_code, response.text)
return None
st.title("らるtalk βv4")
def add_message(message, is_user=True):
chat_history.append({"message": message, "is_user": is_user})
with open(data, "wb") as f:
pickle.dump(chat_history, f)
st.write("")
for entry in chat_history:
if entry["is_user"]:
print("aaa")
else:
st.markdown(f"**らる:** {entry['message']}")
user_input = st.text_input("prompt", key="user_input")
if user_input:
ai_response = send_inference_request(user_input)
if ai_response:
add_message(user_input)
add_message(ai_response, False)

上記のコードを実行するには、コマンドプロンプトで
python -m venv 仮想環境名
pip install streamlit requests pickle
仮想環境名\Scripts\activate
streamlit run ファイルのパスを実行してください。ブラウザが開くと思うので、そこで試してください。
まとめ
どうでしたでしょうか?ここを見てためになればいいですがまだまだ不安定です。
またいい感じのものが作れたら更新します
https://github.com/rintaro-s/LMstudio-client 一応コードはここに置きます
ありがとうございました。

とある高専生。
AIとネットが好き。
将来はAIの妹と火星に住みたい。
discord : r_nightcore
このサイトの管理者。
コメント